我现在已经是个重度Agent用户,上个月我在Codex消耗了大约15亿的token,正好昨天(6月2号)OpenAI发布了Codex报告(The Next Era of Knowledge Work),我们讨论一下知识工作者该如何用Agent。
很多人对 Agent 的第一印象,会停留在“帮程序员写代码”,这不怪大家,无论是Claude Code还是Codex,他们的名字里就带着Code(编程),而且这轮Agent的主导技术就是Vibe Coding。
过去几年,AI 最容易被看见的能力,首先出现在代码场景里:补全函数、修 bug、生成脚本、跑测试、改项目文件。代码有明确结构,有可执行反馈,有相对清晰的对错边界,所以它天然适合成为 Agent 的早期试验场。
但 OpenAI 6 月 2 日发布的报告The Next Era of Knowledge Work提醒我们:Agent 的使用场景正在越过软件开发,进入更广泛的知识工作。

报告中的一句话很关键:Codex 已经不只是 coding tool(代码工具)。它正在帮助不同职业的人自动化日常工作、穿过现代知识工作的瓶颈,并把复杂任务组织成可交付的工作流。
这不是一个简单的“AI 提效”故事。更值得教育研究者和实践者注意的是:Agent 正在改变知识工作者和工具之间的关系。
一、知识工作缺乏通用工具
今天的知识工作者并不缺少软件。恰恰相反,我们的软件太多了:邮件、文档、表格、聊天记录、会议纪要、网盘、知识库、项目管理工具、学习管理系统。
每一个工具都解决了一个局部问题,却共同制造了一个更大的问题:工作信息被切碎了。我在不同的软件都创作或者收藏了很多有用的东西,但我该用的时候总是找不到。
报告把知识工作的日常成本概括为三类摩擦:
第一是搜索(search),也就是找到相关输入的成本。正确文件在哪里?哪份材料是最新版本?哪个数据表才可信?哪条消息里有关键决定?
第二是协调(coordination),也就是让信息和决定在不同人、不同工具、不同格式之间流动的成本。很多工作不是不会做,而是卡在转述、同步、等待、重排和对齐上。
第三是审批与验证(approval and verification),也就是让成果被接受、被检验、经得起现实检查的成本。工程里是测试、审查和部署;法律和咨询里是合伙人审核和客户接受;研究里是证据、复核和可辩护的推理。
这三个词很适合拿来解释今天很多教师、研究者和行政人员的疲惫。
我们可以自己写报告做表格,也并非反感开会,但我们为了完成这些工作,花了更多时间在找上下文、补材料、搬运格式、等待反馈、修订版本、确认责任。
知识工作变得更数字化了,却也更碎片化了。
二、为什么说Agent 是“知识工作的下一阶段”
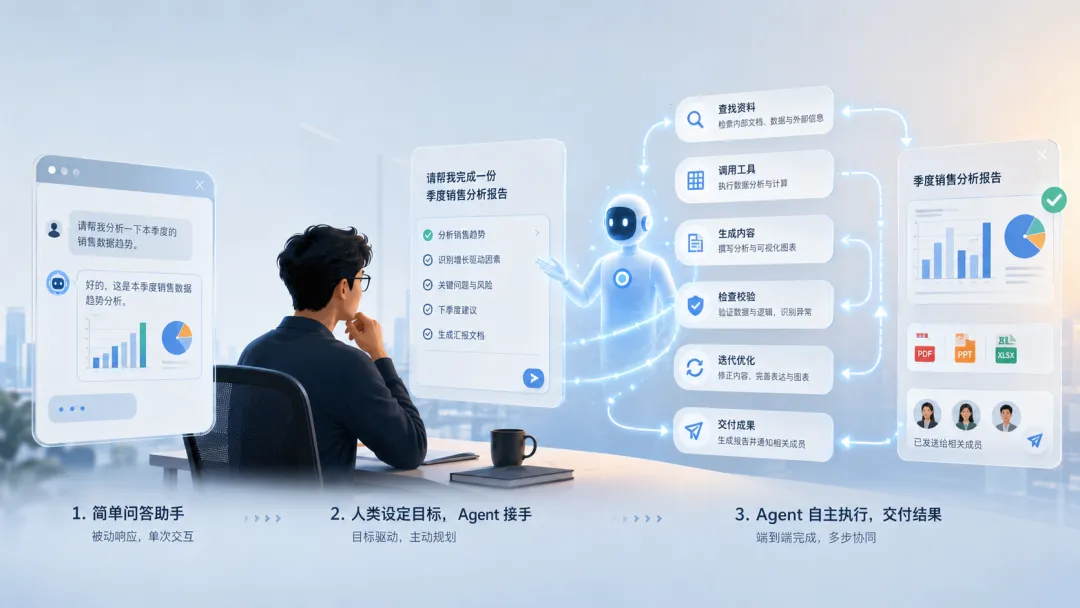
一个普通聊天机器人可以回答问题、写一段话、给一个建议。但知识工作中的真实任务往往不是一个答案,而是一段流程:找材料、理解目标、调用工具、生成文件、检查错误、根据反馈修改、把结果交给下一个环节。
Codex报告里的一个关键比喻是:过去的办公软件降低了“生产文档、邮件、表格、PPT”的成本,但没有降低“理解、核验、协调、推进这些东西”的注意力成本。于是,邮件越方便,邮件越多;文档越容易写,版本越多;会议纪要越容易生成,真正需要判断的东西越容易淹没
OpenAI 想把 Codex 放在这个位置上:它不只是帮人写代码,而是帮人把一个问题拆成可执行任务,去找资料、写脚本、处理表格、生成报告、搭小工具、同时推进多个任务。OpenAI 官方页面称,Codex 已经有超过 500 万周活跃用户,自 2 月桌面应用发布以来增长超过 6 倍;知识工作者约占用户的 20%,增长速度超过开发者 3 倍。
报告里最有意思的数据是任务结构。知识工作者每周使用 Codex 时,72% 会生成某种“知识工件”,包括报告、备忘录、合同、图片、音频、视频、PDF 和电子表格;此外还有工程运维 47%、代码实现 46%、研究 41%。这说明边界正在模糊:开发者会让 Codex 写报告,非程序员也会让 Codex 写脚本、搭仪表盘、清洗数据。
当然,我们不需要了解这些增长数字,更有价值的是报告中的几个案例。
三、案例一:把分散公共信息变成可用的知识库
GroundVue 的案例很典型。
这家公司帮助政府机构相互学习,把公共会议变得可搜索、可比较。问题是,美国大约 9 万个政府机构的关键信息分散在视频、网页和地方平台中。过去,要找到并整理这些公共资料,需要大量技术人员和研究人员。
报告说,GroundVue 使用 Codex 寻找难以触达的公共来源,并建立持续收集、整理这些信息的系统。原来需要数天或数周的任务,现在可以压缩到数分钟。
这个案例的重点不是“AI 搜索更快”,而是 Agent 帮团队把碎片公共信息变成可用的 institutional knowledge。
对教育研究也一样。很多研究者最痛苦的不是没有资料,而是资料散落在政策文件、地方简报、学校案例、论文、会议纪要和个人笔记里。真正有价值的 AI 工作台,可以帮研究者把材料组织成可追溯、可比较、可更新的知识系统。
四、案例二:小团队把客户发现、方案设计和产品验证连起来
Proaction 是一个五人创业团队,帮助车队管理车辆和设备。它面对的客户问题很复杂:数据分散在远程信息系统、维护平台、电子表格和机构记忆中。
报告中的关键细节是:Proaction 的联合创始人 Colin Knudsen 用 Codex 把客户对话转化为定制方案、工作流原型和可运行 demo。也就是说,Agent 把 customer discovery、sales 和 product development 连接在一起。
这很像许多学校或教育机构的项目。
一个真实问题往往不会乖乖待在一个部门里。比如“减轻教师行政负担”既涉及流程,也涉及平台,也涉及评价,也涉及数据权限。过去,一线教师提出问题,管理者整理需求,技术团队排期开发,中间经过多轮转述,问题常常被改写得面目全非。
Agent 的潜力在于,它让最接近问题的人可以先做一个可运行原型:把对话整理成需求,把需求转成流程,把流程变成小工具,再用真实反馈修正它。
这不是取消专业分工,而是减少“问题到工具”之间的长距离转运。
五、案例三:大学教师把行政维护时间拿回来
报告里也有一个来自教育领域的案例,加州州立大学数学教授 Taiyo Inoue(井上太阳)介绍了自己的工作流。
他用 Codex 生成脚本,自动更新 Canvas 学习管理系统里的作业、日历、课程材料和通知。报告说,这个工作流每周为他节省大约 4 到 5 小时。
真正值得讲的不是“教授学会用Agent”,而是节省下来的时间去了哪里。
报告提到,Inoue 把这些时间重新投入课堂,把课程设计成更多面对面的协作问题解决活动。
这个案例特别适合提醒教育读者:AI 减负的意义,不是让教师继续接更多行政工作,而是把教师从低价值的管理维护中释放出来,重新靠近学生、问题和教学判断。
在教育场景里,Agent 最有价值的任务,可能并不是写一份漂亮教案,而是清理那些长期吞噬教师注意力的后台工作:同步课程表、整理材料版本、追踪学生提交、生成反馈记录、汇总家校沟通、维护平台信息。
如果这些工作被更好地代理,教师才可能把节省下来的时间投入真正需要人的地方。
六、我的尝试和反思
这份报告在提醒我们:Agent 正从程序员工具扩展为知识工作者的自我管理系统。
讲了三个别人的案例,我也讲个自己的案例吧。
我从2017年起养成了读电子书的习惯,我会在平台上划线以及写下自己的笔记。最近我发现,我已经积累了超过13000条笔记,于是我把这些笔记全部导出,在自己的电脑上做了个专门的项目文件,让Codex整理,并做了一套”李小祖逸.skill“。
这个很简单,微信读书和得到大脑这些平台都开源了自己的笔记.skill,仿照他们的模式很快帮你设计一个本地版。
现在我写东西,只要问:我有哪些笔记可以用到这篇文章?Agent就会告诉我我有哪些相关笔记,可以怎么用。
但我又开始反思另一些问题,我这个月用了15亿的token,这全是调用的GPT-5.5模型,其实成本很高的。
GPT告诉我,现在你的用量已经到了“小型工作室”的水平,已经进入了需要管理“算力资本”的阶段。
我开始想,我花了这么多的资源,有没有产出同等的价值呢?毕竟我是自费,得考虑这些成本和回报的问题。我可以试错,但我不能浪费;我可以消耗,但我应该要求自己有所产出。
于是我们形成了一套“吾日三省吾身(算力资本管理篇)”:
一省其耗:哪些 token 的花费无节制的浪费?
二省其试:哪些 token 的花费是有意义的试错?
三省其值:花掉这么多 token,是否创造了相称的价值?
余不一一

原报告链接:https://cdn.openai.com/pdf/the-next-era-of-knowledge-work.pdf