凌晨两点,你终于把那份可靠性评估报告写完了。
术语准确、逻辑顺畅、排版漂亮。你甚至觉得,这是这季度写得最好的一份。
第二天评审会,总工翻了两页,抬头问了一句:“这个失效率的结论,依据是哪份数据?”
你说不上来。报告是你用通用 AI 辅助写的——它读起来像那么回事,但你确实不知道那些数字是从哪条记录、哪个版本里来的。
这种感觉并非个例。恰恰相反,它是当下可靠性工程里最普遍的“应用落差”。
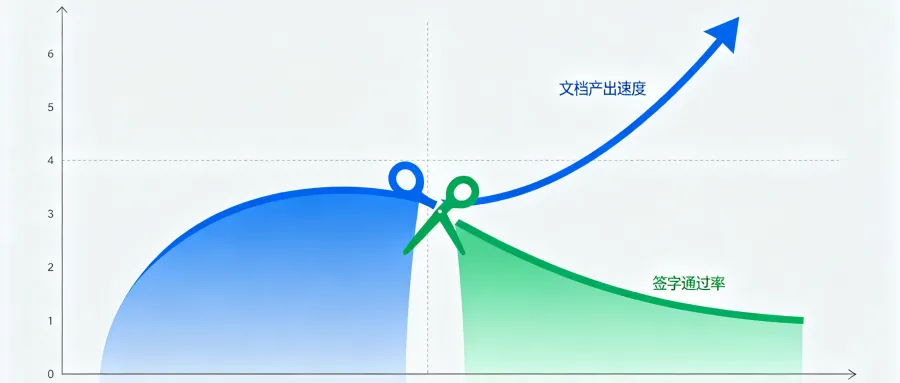
上一回我们说到:对现成 AI不满意,问题往往不在模型够不够大。今天把镜头拉近一点——同一批问卷里,有一组数字放在一起读,像一把剪刀。
年初我们做了结构化收集,66 道题,有效样本约900+。在已经用过 AI 的同行里,最常见的用法并不是你想象的专业建模,而是一件更朴素的事:报告/文档撰写,占到约四成(多选口径)。
与此同时,大家最希望 AI 帮忙的业务是什么?排在前列的是 FMEA 智能分析与填写、故障诊断与预测性维护、试验方案优化——每一项单独看都不算小众,合在一起指向同一句话:大家想让AI 往里走,走到表格里、走到试验数据和失效链条里。
一边是“写得多”——先把周报、说明、段落排版搞定;一边是“想得深”——最好能把 FMEA、诊断、试验几件事一起扛起来。两道弧线没有对上,就出现了剪刀差:写得越快,并不代表签得越干脆;排版越漂亮,也不代表依据已经对齐到你们家的那张表。
这不是工程师偷懒,是工作的真实结构:文档输出成本低,责任成本高。 可靠性最让人睡不着觉的,从来不是“今晚能不能把报告编好”,而是——明天开会,谁来回答那句“依据在哪"。